
Safeguarding AI: A Policymaker’s Primer on Adversarial Machine Learning Threats
Note: Mumtaz Fatima is the primary author of this post.
Artificial intelligence (AI) has become increasingly integrated into the digital economy, and as we’ve learned from the advent of the internet and the expansion of Internet-of-Things products and services, mass adoption of novel technology comes with widespread benefits as well as security tradeoffs. For policymakers to support the resilience of AI and AI-enabled technology, it is crucial for them to understand malicious attacks associated with AI integration, such as adversarial machine learning (ML); to support responsible AI development; and to develop robust security measures against these attacks.
Adversarial Machine Learning Attacks
Adversarial ML attacks aim to undermine the integrity and performance of ML models by exploiting vulnerabilities in their design or deployment or injecting malicious inputs to disrupt the model’s intended function. ML models power a range of applications we interact with daily, including search recommendations, medical diagnosis systems, fraud detection, financial forecasting tools, and much more. Malicious manipulation of these ML models can lead to consequences like data breaches, inaccurate medical diagnoses, or manipulation of trading markets. Though adversarial ML attacks are often explored in controlled environments like academia, vulnerabilities have the potential to be translated into real-world threats as adversaries consider how to integrate these advancements into their craft. Adversarial ML attacks can be categorized into white-box and black-box attacks based on the attacker’s ability to access the target model.
White-box attacks imply that the attacker has open access to the model’s parameters, training data, and architecture. In black-box attacks, the adversary has limited access to the target model and can only access additional information about it through application programming interfaces (APIs) and reverse-engineering behavior using output generated by the model. Black-box attacks are more relevant than white-box attacks because white-box attacks assume the adversary has complete access, which isn’t realistic. It can be extremely complicated for attackers to gain complete access to fully trained commercial models in the deployment environments of the companies that own them.
Types of Adversarial Machine Learning Attacks
Query-based Attacks
Query-based attacks are a type of black-box ML attack where the attacker has limited information about the model’s internal workings and can only interact with the model through an API. The attacker submits various queries as inputs and analyzes the corresponding output to gain insight into the model’s decision-making process. These attacks can be broadly classified into model extraction and model inversion attacks.
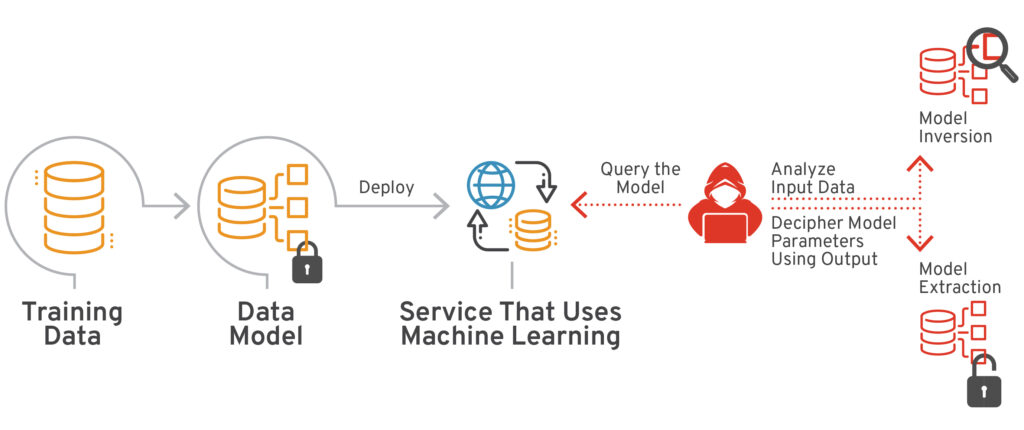
Figure 1 – Explaining query-based ML attacks (Source: Adversarial Robustness Toolbox)
Model Extraction: The attacker’s goal is to reconstruct or replicate the target model’s functionality by analyzing its responses to various inputs. This stolen knowledge can be used for malicious purposes like replicating the model for personal gain, conducting intellectual property theft, or manipulating the model’s behavior to reduce its prediction accuracy.
Model Inversion: The attacker attempts to decipher characteristics of the input data used to train the model by analyzing its outputs. This can potentially expose sensitive information embedded in the training data, raising significant privacy concerns related to personally identifiable information of the users in the dataset. Even if the model’s predictions are not directly revealing, the attacker can reconstruct the outputs to infer subtle patterns or characteristics about the training dataset. State-of-the-art models offer some resistance to such attacks due to their increased infrastructure complexity. New entrants, however, are more susceptible to these attacks because they possess limited resources to invest in security measures like differential privacy or complex input validation.
Data Poisoning Attacks
Data poisoning attacks occur in both white- and black-box settings, where attackers deliberately add malicious samples to manipulate data. Attackers can also use adversarial examples to deceive the model by skewing its decision boundaries. Data poisoning occurs at different stages of the ML pipeline, including data collection, data preprocessing, and model training. Generally, the attacks are most effective during the model training phase because that is when the model learns about different elements within the data. Such attacks induce biases and reduce the model’s robustness.
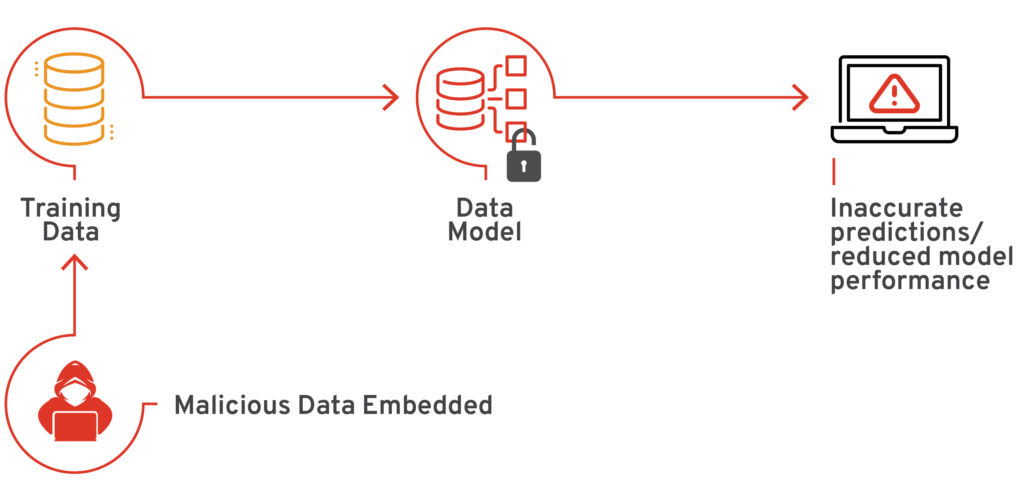
Figure 2 – Explaining data poisoning attack (Source: Adversarial Robustness Toolbox)
Adversaries face significant challenges when manipulating data in real time to affect model output thanks to technical constraints and operational hurdles that make it impractical to alter the data stream dynamically. For example, pre-trained models like OpenAI’s ChatGPT or Google’s Gemini trained on large and diverse datasets may be less prone to data poisoning compared to models trained on smaller, more specific datasets. This is not to say that pre-trained models are completely immune; these models sometimes fall prey to adversarial ML techniques like prompt injection, where the chatbot either hallucinates or produces biased outputs.
Protecting Systems Against Adversarial Machine Learning Attacks
Addressing the risk of adversarial ML attacks necessitates a balanced approach. Adversarial attacks, while posing a legitimate threat to user data protections and the integrity of predictions made by the model, should not be conflated with speculative, science fiction-esque notions like uncontrolled superintelligence or an AI “doomsday.” More realistic ML threats relate to poisoned and biased models, data breaches, and vulnerabilities within ML systems. It is important to prioritize the development of secure ML systems alongside efficient deployment timelines to ensure continued innovation and resilience in a highly competitive market. Following is a non-exhaustive list of approaches to secure systems against adversarial ML attacks.
Secure-by-design principles for AI development: One method to ensure the security of an ML system is to employ security throughout its design, development, and deployment processes. Resources like the U.S. Cybersecurity and Infrastructure Security Agency and U.K. National Cyber Security Centre joint guidelines on secure AI development and the National Institute of Standards and Technology (NIST) Secure Software Development Framework provide guidance on how to develop and maintain ML models properly and securely.
Incorporating principles from the AI Risk Management Framework: NIST’s AI Risk Management Framework (RMF) is a flexible framework to address and assess AI risk. According to the RMF, ML models should prioritize anonymity and confidentiality of user data. The AI RMF also suggests that models should consider de-identification and aggregation techniques for model outputs and balance model accuracy with user data security. While specialized techniques for preventing adversarial ML attacks are essential, traditional cybersecurity defensive tools like red teaming and vulnerability management remain paramount to systems protection.
Supporting new entrants with tailored programs and resources: Newer players like startups and other smaller organizations seeking to integrate AI capabilities into their products are more likely to be vulnerable to these attacks due to their reliance on third-party data sources and any potential deficiencies in their technology infrastructure to secure their ML systems. It’s important that these organizations receive adequate support from tailored programs or resources.
Risk and threat analysis: Organizations should conduct an initial threat analysis of their ML systems using tools like MITRE’s ATLAS to identify interfaces prone to attacks. Proactive threat analysis helps organizations minimize risks by implementing safeguards and contingency plans. Developers can also incorporate adversarial ML mitigation strategies to verify the security of their systems.
Data sanitization: Detecting individual data points that hurt the model’s performance and removing them from the final training dataset can defend the system from data poisoning. Data sanitization can be expensive to conduct due to its need for computational resources. Organizations can reduce the risk of data poisoning with stricter vetting standards for imported data used in the ML model. This can be accomplished through data validation, anomaly detection, and continual monitoring of data quality over time.
Because these attacks have the potential to compromise user data privacy and undermine the accuracy of results in critical sectors, it is important to stay ahead of threats. Understanding policy implications and conducting oversight is essential, but succumbing to fear and hindering innovation through excessive precaution is detrimental. Policymakers can foster environments conducive to secure ML development by providing resources and frameworks to navigate the complexities of securing ML technologies effectively. A balance between developing resilient systems and sustained innovation is key for the United States to maintain its position as a leading AI innovator.